Meilisearch とは?
Meilisearch は、簡単に使えることをポリシーとして作られた OSS のサーチエンジンで、これを利用すると、アプリの フロントエンドに高速な検索機能 を組み込むことができます。 個人や中小企業でも手軽に導入でき、柔軟な設定により様々な用途に対応できます。 Meilisearch には次のような特徴があります。
- 高速な応答(検索結果は 50 ミリ秒以内に得られる。ただし、1,000 万件以上の大規模なデータは想定していない)
- インクリメンタルサーチ(入力するたびにプレフィックスで絞り込んで結果を返す)
- タイポ入力補正(検索語句を多少間違えて入力してもそれっぽい単語で検索してくれる)
- プレースホルダー検索(キーワードを入力せずにカテゴリーなどで結果を絞り込む)
- カスタムランキング処理(ranking rules による検索結果のソート)
- 検索結果のハイライト表示(入力キーワードに一致した位置がわかる)
- 日本語を含む各種言語に対応(形態素解析エンジンに Lindera を採用)
- 同義語の定義
Meilisearch は 簡単であること を哲学としているので、類似の検索フレームワークに比べて全体的にシンプルな構成になっています。 Elasticsearch などでは大袈裟すぎるというニーズにマッチするかもしれません。 JSON 形式のドキュメントを REST API で登録してインデックスを作成するだけで、REST API による検索が可能になります。 最終的にはフロントエンドから直接 REST API を呼び出すように UI を作り込んでいく必要がありますが、プレビュー用の Web サーバー(ダッシュボード UI)が内蔵されているので、コーディングなしでインクリメンタルサーチを試すことができます。

似たような検索エンジンとしては、Algolia という SaaS があります。 Meilisearch は Algolia にインスパイアされて作られているので、アルゴリズム等は似ていますが、オープンソース であるという大きな違いがあります(Algolia は個人で使うには高すぎるというのもあります…)。
Meilisearch サーバーを起動する
Docker Hub に getmeili/meilisearch というイメージが公開されているので、これを使えば簡単に Meilisearch のサーバーを立ち上げることができます。
docker run --rm -it -p 7700:7700 \
-v $(pwd)/meili_data:/meili_data \
getmeili/meilisearch:v1.6docker runのオプションの意味:--rm… コンテナを停止したときに、コンテナを自動で削除します。-it… ターミナルとコンテナの標準入出力を連動させます。-p 7700:7700…localhost:7700へのアクセスをコンテナの 7700 番ポート(Meilisearch サービス)へ転送します。-v $(pwd)/meili_data:/meili_data… カレントディレクトリのmeili_dataディレクトリを、Meilisearch のデータ格納先として使用します。ディレクトリが存在しない場合は、自動で作成されます。getmeili/meilisearch:v1.6… 使用する Meilisearch イメージを指定しています。最新バージョンのタグは Docker Hub 上で確認してください。
Meilisearch はデフォルトで development モード (--env=development) で起動し、プレビュー用の UI を提供します。
コンテナが起動したら、ブラウザで http://localhost:7700/ にアクセスすると、Meilisearch のダッシュボードを表示できます。
プライマリーフィールド
Meilisearch を使い始めるときは、最初に プライマリーフィールド の概念を理解しておく必要があります。
Meilisearch に登録するデータのことを ドキュメント と呼びますが、各ドキュメントには必ず、プライマリーフィールドと呼ばれる一意の ID フィールドが必要です。 逆に言うと、これ以外のフィールドの値は、どれだけ重複していても大丈夫です。 同一のドキュメント ID を持つドキュメントを登録しようとすると、古いドキュメントは上書きされます。

多くの場合、プライマリーフィールドのキー名(プライマリーキー)は、id といった名前ですが、インデックスを作成するときに任意のキー名を指定することができます。
キー名を省略すると、1 つ目のドキュメントから id を含む名前のキーが自動的に選択されます(例: id、bookId、todo-id)。
インデックスにドキュメントを登録するとき、そのフィールドにプライマリーキーが見つからない場合は登録に失敗します。
ドキュメント ID が不正な形式の場合も登録に失敗します。
ドキュメント ID は、整数値、あるいは、英数字 (a-zA-Z0-9)、ハイフン (-)、アンダースコア (_) のみで構成された文字列である必要があります。
"id": 12345 // Good
"id": "a39NfE2" // Good
"id": "x-12_34" // Good
"id": 0.12345 // NG(浮動小数点数はダメ)
"id": "df/3 #@" // NG(不正な記号やスペース)インデックスの作成とドキュメントの追加
Meilisearch で検索を行えるようにするには、インデックスを作成して、そこに JSON 形式のドキュメントを投入していく必要があります。
それぞれの作業を独立して行うこともできますし、ドキュメントを追加するときに同時にインデックスを作成してしまうこともできます。
Meilisearch の操作方法としては、各種言語用のライブラリが提供する API を使う方法と、REST API を直接呼び出す方法があります。
ここでは curl コマンドで直接 REST API を呼び出して、インデックスの作成とドキュメントの追加をしてみます。
あるインデックスに対してドキュメントを追加するには、/indexes/<インデックス名>/documents というエンドポイントに POST メソッドで JSON 形式のデータを送ります。
次の例では、books という名前のインデックスを作成し、そこに 3 つの書籍情報(ドキュメント)を登録しています。
curl -X POST 'http://localhost:7700/indexes/books/documents?primaryKey=id' \
-H 'Content-Type: application/json' \
--data-binary '[
{ "id": 1, "title": "みんなの Meili", "author": "名無し" },
{ "id": 2, "title": "Meili かわいい", "author": "John Doe" },
{ "id": 3, "title": "Best of Meili", "author": "Maku" }
]'前述の通り、id というキーを自動的にプライマリーキーとして採用してくれますが、上記のように primaryKey=id でキー名を明示することもできます。
次のように処理内容が出力されれば成功です。
{"taskUid":3,"indexUid":"books","status":"enqueued","type":"documentAdditionOrUpdate","enqueuedAt":"2023-01-24T07:02:22.4346468Z"}多数のドキュメントを登録したいときは、次のような JSON ファイルとしてデータを用意しておき、
[
{ "id": 1, "title": "みんなの Meili", "author": "名無し" },
{ "id": 2, "title": "Meili かわいい", "author": "John Doe" },
{ "id": 3, "title": "Best of Meili", "author": "Maku" }
]次のように Meilisearch のインデックスに登録します(ファイル名の前に @ プレフィックスを付けます)。
curl -X POST 'http://localhost:7700/indexes/books/documents?primaryKey=id' \
-H 'Content-Type: application/json' --data-binary @books.jsonMeilisearch サービスに現在登録されているインデックスの一覧を確認するには、/indexes というエンドポイントに GET リクエストを投げます。
$ curl -X GET http://localhost:7700/indexes?limit=3
{
"results": [
{
"uid": "books",
"createdAt": "2023-01-24T06:47:13.0555429Z",
"updatedAt": "2023-01-24T07:10:13.2373666Z",
"primaryKey": "id"
}
],
"offset": 0,
"limit": 3,
"total": 1
}
正しく、books というインデックスが作成されているようです。
まだインデックスは 1 つしか作成していないので、total フィールドの値は 1 になっています。
ドキュメントを取得する
すべてのドキュメントを取得する
/indexes/{index_uid}/documents に GET 要求を送ると、すべてのドキュメントを取得できます。
ただし、limit パラメーターのデフォルト値は 20 です。
$ curl http://localhost:7700/indexes/books/documents?limit=3
/indexes/{index_uid}/documents/{document_id} に GET 要求を送ると、指定したドキュメント ID に一致するドキュメントを取得できます。
$ curl http://localhost:7700/indexes/books/documents/1
ドキュメントを検索する
/indexes/{index_uid}/search に GET あるいは POST 要求を送ると、任意の検索文字列(q パラメーター)でドキュメントを検索できます。
この API が Meilisearch による検索のキモとなる API です。
$ curl http://localhost:7700/indexes/books/search?q=Meili
実運用上は、検索速度の向上のため GET リクエストではなく、POST リクエストを使用する 必要があります(HTTP のプリフライト・リクエストのキャッシュが有効になる)。
$ curl -X POST 'http://localhost:7700/indexes/books/search' \
-H 'Content-Type: application/json' \
--data-binary '{ "q": "Meili" }'ちょっと綴りを間違えて、「Meilli」と入力してもうまく検索してくれます。 (*>ω<)bグッ
日本語で検索する場合は、検索文字列を URL エンコードしておく必要があるかもしれません。
$ curl http://localhost:7700/indexes/books/search?q=%E3%81%8B%E3%82%8F%E3%81%84%E3%81%84
他にも様々なクエリパラメーターが用意されていて、ページングやソート方法などを指定できるようになっています。 詳細は Search API のドキュメント を参照してください。
ダッシュボードで確認する
インデックスに登録されたドキュメントは、http://localhost:7700 で表示されるダッシュボード (Mini Dashboard) からも検索できるようになっています。
ちなみにこれはテスト用の UI で、開発モード (--env=development) として起動した場合だけ有効になっています(デフォルトは開発モードです)。
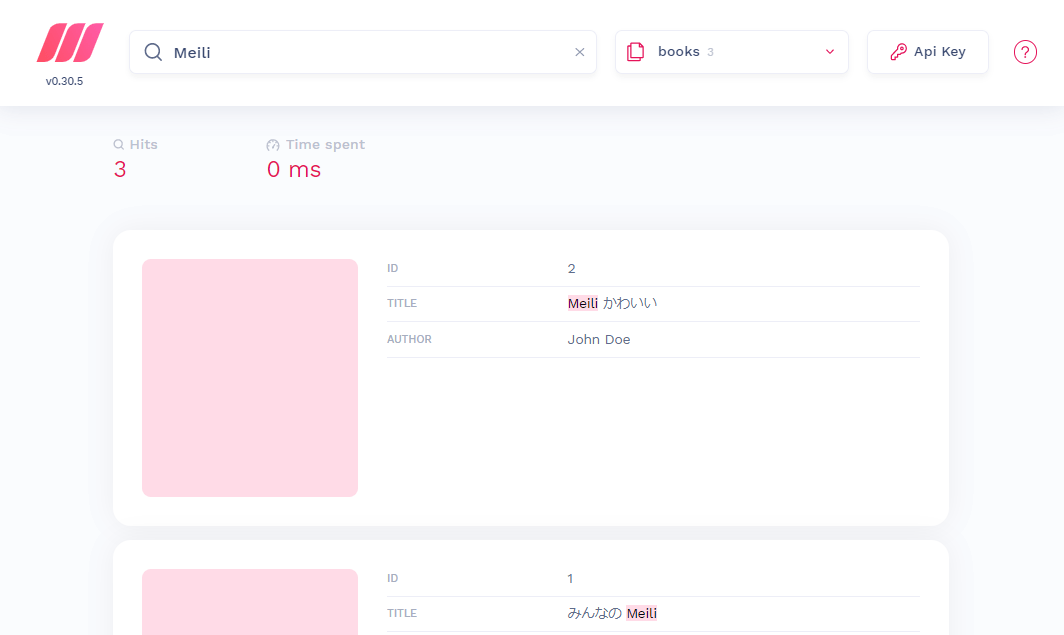
うまくいきました! ٩(๑❛ᴗ❛๑)۶ わーぃ
(おまけ)テレメトリデータを送らない設定
Meilisearch はプロダクト改善のために、デフォルトで テレメトリデータ を収集しています。
データベース内の情報が送信されるようなことはありませんが、社内プロジェクトなどで、いかなるデータも送りたくない場合は、meilisearch サーバー起動時に --no-analytics オプションを指定します。