
用語まとめ
- character map / charmap
- 特定のエンコーディングの文字コードを、glyph index にマッピングするための情報。1つの Font face は複数の charmap を含んでいることが多い。Mac 用の charmap、Unicode(Windows)の charmap など。
- charset / 文字セット
- 「文字集合」と「エンコーディング」をセットにした概念。IANA が定義した。
- font collection
- 複数の font face を 1 つのファイルに含んだもの。
- font face
- font family に、Italic とか Bold とかの区別を加えたもの(ノーマルなものは Regular)。
- font family
- Arial とか Courier とか。
- glyph
- 文字を描画したときの形。フォントファイルは、ビットマップで glyph を持つこともあるし、ベクターデータで glyph を持つこともある。
- ligature
- 合字。2文字以上をくっつくて1文字を表現したもの。
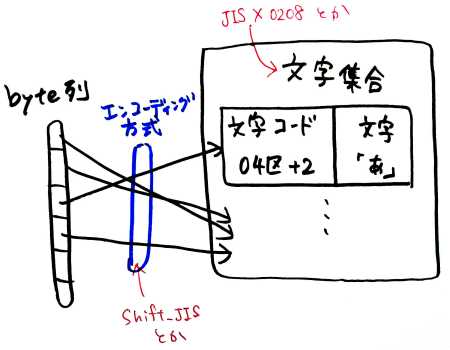
- エンコーディング形式 / 文字符号化方式 / CES: Character Encoding Scheme
- 文字集合内の文字に割り当てられた数値を、コンピュータが実際に使用するバイト列に対応付ける方法。例: Shift_JIS、EUC-JP、ISO-2022-JP
- スクリプト
- スクリプト(書体)は言語の文字情報を表す記号の集まりです。スクリプトの例には、ラテン文字、アラビア文字、漢字、ギリシャ文字があります(参考: http://unicode.org/reports/tr24/ )。
- 文字コード
- 文字に割り当てられた数値(バイト表現)のこと。まれに、エンコーディング形式のことを文字コードといったりする。例:
0x0102 - 文字集合 / 符号化文字集合
- 文字コードの集合。文字の見た目が同じであったとしても、文字集合ごとに、割り当てられる文字コードは異なる。例: JIS X 0208(JIS拡張漢字)
「文字集合」と、それに適用できる「エンコーディング形式」には関連があります。
例えば、文字集合 JIS X 0208 で使われるエンコーディング形式は ISO-2022-JP、EUC-JP、Shift_JIS などです。
Unicode について
Unicode の登場以前は、日本語は JIS X 0208 という文字集合、中国語繁体字は Big5 という文字集合、のように、文字の種類ごとに文字集合を使い分けることが普通でしたが、Unicode ではすべての文字を 1 つの文字集合で表現します。 JIS X 0208 文字集合に含まれていた文字は、すべて Unicode に含まれています。