
何をするか?
Firestore データベースは、コレクションデータを手軽に格納していくのにはとても便利ですが、全データを集計するような処理は苦手です。 例えば、各ドキュメントに付けられた「タグ」情報をすべて回収して、タグの一覧を生成したい場合、全てのドキュメントを read する必要があるため、ドキュメント数が Firebase の使用料金にダイレクトに効いてきます。 もし、Firestore にドキュメントが追加されるたびに Cloud Functions を起動してこのような集計処理を行うと、凄まじい勢いで課金されてしまいます。
ここでは、Cloud Functions による 集計処理を定期的なスケジュールで起動する ことで、Firestore ドキュメントの read 処理を削減してみます。 もちろん、リアルタイムな更新が必要なデータには使えませんが、カタログ的なデータであれば、定期的なデータ更新で間に合うケースは多いはずです。
事前準備
- Firebase コンソール からテスト用のプロジェクトを作成してください。ここでは、自動生成されたアプリ ID を
myapp-58138とします。 - Firestore データベースに
booksコレクションを追加し、次のようなサンプルドキュメントを追加してください。tagフィールドは本来は配列 (tags) であるべきですが、ここではシンプル化のために文字列型のスカラデータとしています。- id:
001(title:Title1, author:Author1, tag:Tag1) - id:
002(title:Title2, author:Author2, tag:Tag2) - id:
003(title:Title3, author:Author3, tag:Tag3)
- id:
- Firebase CLI をインストール して、
firebaseコマンドを使用できるようにしてください。作成した関数を Cloud Functions にデプロイするために使います。
プロジェクトの雛形の生成
プロジェクト用のディレクトリを作成します。
$ mkdir myapp
$ cd myapp
firebase init コマンドを実行して、Cloud Functions をデプロイするための firebase.json ファイルと、関数実装のテンプレート (functions/*) を作成します。
$ firebase init functions
次のような感じで質問に回答していけば OK です。 ESLint のスタイルはプロジェクトによって異なるので、ここでは自動設定しないようにしています。
- ? Please select an option:
Use an existing project - ? Select a default Firebase project for this directory:
myapp-58138 (MyApp) - ? What language would you like to use to write Cloud Functions?
TypeScript - ? Do you want to use ESLint to catch probable bugs and enforce style?
n - ? Do you want to install dependencies with npm now?
y
集計用 Cloud Functions の作成
Cloud Functions のテンプレートコードとして、functions/src/index.ts というファイルが生成されているので、このファイルを修正することにします。
ここでは、次のような処理を 60 分おきに実行 するように実装しています。
booksコレクション内のすべてのドキュメントからタグ情報を回収(collectTags関数)- タグの配列を
meta/booksMetaドキュメントのtagsフィールドに保存(updateMeta関数)
import * as admin from 'firebase-admin'
import * as functions from 'firebase-functions'
admin.initializeApp()
const booksCollRef = admin.firestore().collection('books')
const booksMetaRef = admin.firestore().doc('meta/booksMeta')
/** 定期的にメタ情報を更新する関数。 */
exports.updateMetaFunction = functions
.region('asia-northeast1')
.pubsub.schedule('every 60 minutes')
.onRun(async (context) => {
console.log('Start updating tags information of books')
const tags = await collectTags()
await updateMeta(tags)
console.log(`tags = ${tags.join(', ')}`)
return null
})
/** books コレクション内のドキュメントからタグ情報を抽出します。 */
async function collectTags(): Promise<string[]> {
const tags = new Set<string>()
const snapshot = await booksCollRef.get()
snapshot.docs.forEach((doc) => {
const book = doc.data()
tags.add(book['tag'])
})
return [...tags].sort() // Set からソート済み文字列配列に変換
}
/** meta コレクションのタグ一覧情報を更新します。 */
async function updateMeta(tags: string[]): Promise<void> {
await booksMetaRef.set({ tags }, { merge: true })
}functions ディレクトリ以下で次のようにしてビルド&デプロイします。
$ npm run deploy
(下記と同様です)
$ firebase deploy --only functions
デプロイが完了するまで数分間待ちます。
実行結果の確認
Firebase コンソールからプロジェクトを開き、Functions のページを開きます。
今回作成した関数は「60 分おき」に実行されるようにスケジューリングしましたが、関数のオプションメニューから Cloud Scheduler で表示 を選択し、関数を手動で 今すぐ実行 することができます。
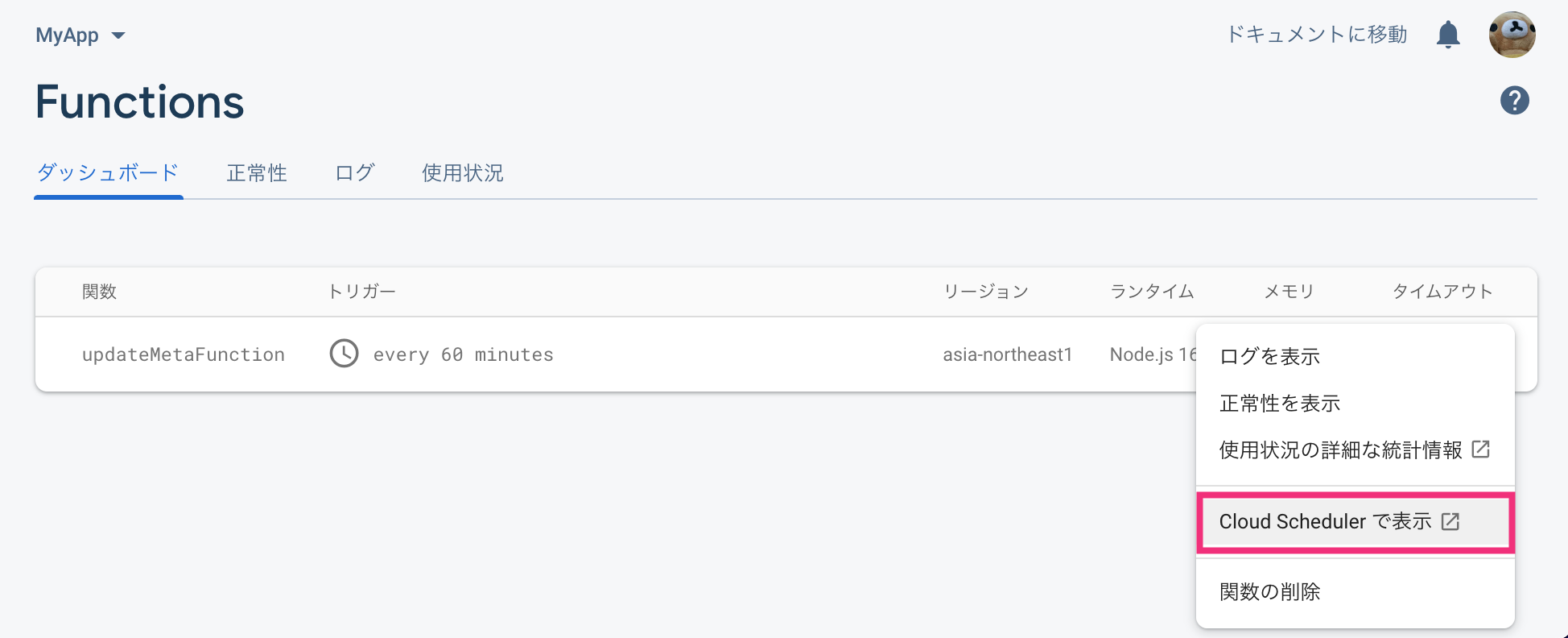
関数が実行されると、Firestore の books コレクションのタグ情報が回収されて、meta/booksMeta ドキュメントに書き込まれます。
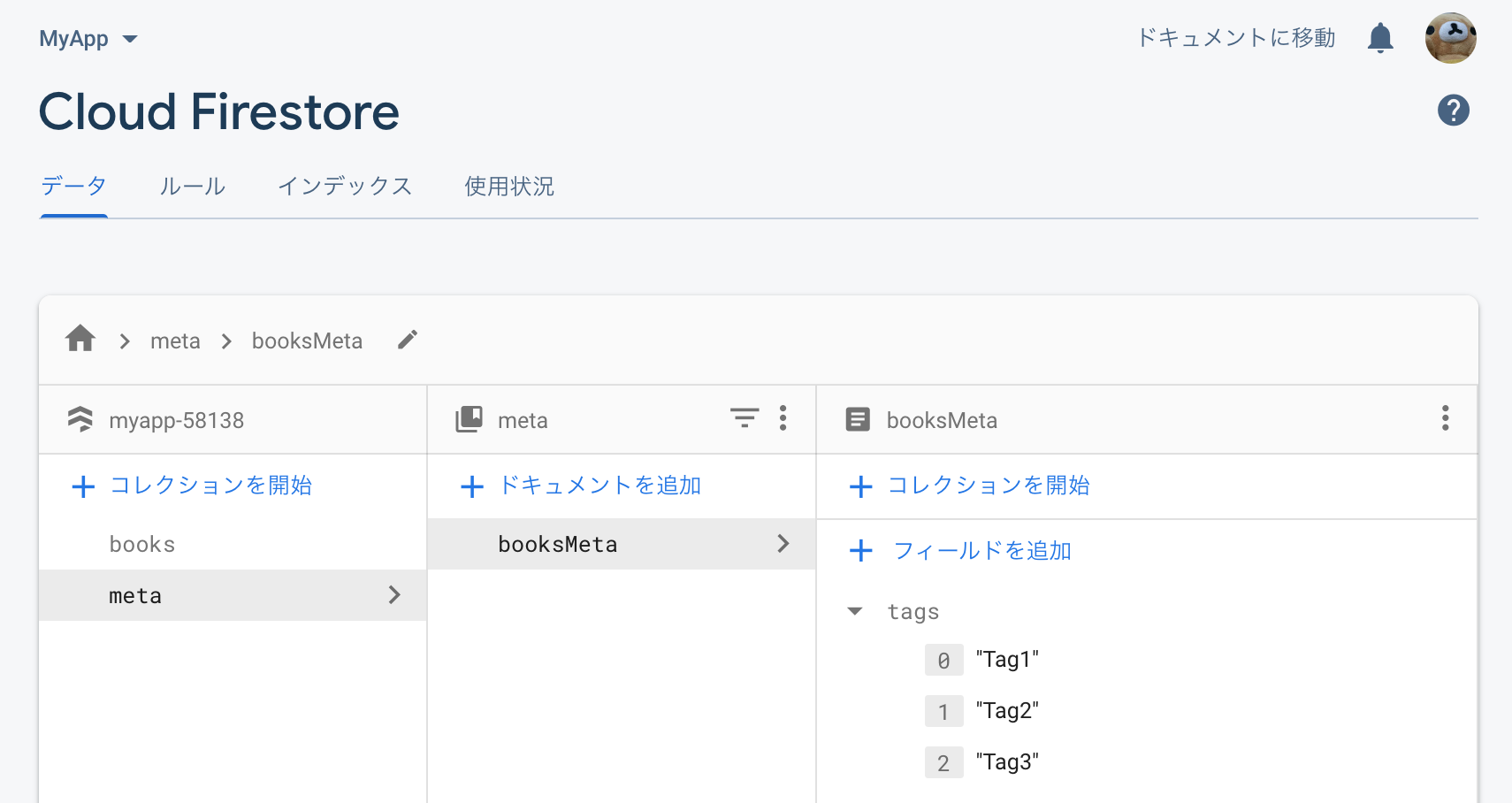
Firestore Database のページを開き、データタブを選択すると、tags フィールドにすべてのタグ情報が格納されていることを確認できます。
さらにドキュメントの read 回数を減らすには
今回、Firestore ドキュメントの集計用関数の呼び出し頻度を 1 時間に 1 回としましたが、ドキュメント数が数万件規模になってくると、これでもドキュメントの read 回数が膨大になってしまいます(Firestore の無料枠は、1 日あたり 50,000 read しかありません)。 データ集計用の read 回数をさらに減らすには、次のような方法が考えられます。
- Cloud Functions の定期実行時に
booksコレクションが更新されているかをチェックして、更新されていない場合は 集計処理をスキップする booksコレクションの更新時に 集計情報を差分更新する
以下、それぞれの方法を見ていきます。
集計処理をスキップする
スケジューリングされた Cloud Functions は定期的に呼び出されますが、このとき books コレクションのデータが何も更新されていないのであれば、全データをスキャンして集計するのは無駄です。
各ドキュメントを更新したときに、updatedAt のようなフィールドを付加しておけば、前回の集計関数が実行されたあとにデータ更新があったかどうかをチェックすることができます(集計データの方にも updatedAt フィールドが必要です)。
ちなみに、クライアントアプリから Firestore のドキュメントを更新するときは、serverTimestamp 関数 の戻り値をフィールド値として設定することで、サーバー側のタイムスタンプを格納することができます。 クライアント PC のシステム時刻は狂っている可能性があるので、このように更新時刻をセットした方が安全です。
import { serverTimestamp, setDoc } from "firebase/firestore";
// ...
const bookDoc = {
title: 'New Title',
author: 'New Author',
tag: 'New Tag',
updatedAt: serverTimestamp() // サーバー側で更新時刻を詰める
}
Cloud Functions でメタ情報を更新するときも、メタ情報側に updatedAt フィールドを格納するようにします。
// import { FieldValue } from 'firebase-admin/firestore'
/** meta コレクションのタグ一覧情報を更新します。 */
async function updateMeta(tags: string[]): Promise<void> {
await booksMetaRef.set(
{ tags, updatedAt: FieldValue.serverTimestamp() },
{ merge: true }
)
}
あとは、定期実行される Cloud Functions の集計関数の中で、上記タイムスタンプを比較して、メタ情報の更新時刻の方が古い場合のみメタ情報を更新するようにします。
更新が必要ない場合は、books コレクション内のドキュメントは 1 つだけ read するだけで済む(最新の updatedAt を持つドキュメントを 1 つだけ read する)ので、Firestore の課金を最小限に抑えられます。
以下にこの対応を入れた Cloud Functions の関数実装を載せておきます。
import * as admin from 'firebase-admin'
import * as functions from 'firebase-functions'
import { FieldValue, Timestamp } from 'firebase-admin/firestore'
admin.initializeApp()
const booksCollRef = admin.firestore().collection('books')
const booksMetaRef = admin.firestore().doc('meta/booksMeta')
/** 定期的に実行する関数。 */
exports.updateMetaFunction = functions
.region('asia-northeast1')
.pubsub.schedule('every 60 minutes')
.onRun(async (context) => {
console.log('Checks if the books are updated')
const needToUpdate = await needToUpdateMeta()
if (!needToUpdate) {
console.log('Books are not updated')
return null
}
console.log('Start updating meta information of books')
const tags = await collectTags()
// console.log(`tags = ${tags.join(', ')}`)
await updateMeta(tags)
return null
})
/** books コレクション内のドキュメントからタグ情報を抽出します。 */
async function collectTags(): Promise<string[]> {
const tags = new Set<string>()
const snapshot = await booksCollRef.get()
snapshot.docs.forEach((doc) => {
const book = doc.data()
tags.add(book['tag'])
})
return [...tags].sort() // Set からソート済み文字列配列に変換
}
/** meta コレクションのタグ一覧情報を更新します。 */
async function updateMeta(tags: string[]): Promise<void> {
await booksMetaRef.set(
{ tags, updatedAt: FieldValue.serverTimestamp() },
{ merge: true }
)
}
/** books コレクションの最終更新日時を取得します。 */
async function lastUpdatedTimeOfBook(): Promise<Timestamp | undefined> {
const booksSnap = await booksCollRef
.orderBy('updatedAt', 'desc')
.limit(1)
.get()
if (booksSnap.empty) {
console.error('updatedAt を持つドキュメントが見つかりません!')
return undefined
}
const latestBook = booksSnap.docs[0].data()
return latestBook['updatedAt']
}
/** メタ情報の最終更新日時を取得します。 */
async function lastUpdatedTimeOfMeta(): Promise<Timestamp | undefined> {
const metaSnap = await booksMetaRef.get()
return metaSnap.data()?.['updatedAt']
}
/**
* メタ情報の更新が必要かどうかを確認します。
* (メタ情報の最終更新後に、books コレクションが更新されていれば true)
*/
async function needToUpdateMeta(): Promise<boolean> {
const bookUpdated = await lastUpdatedTimeOfBook()
if (bookUpdated == undefined) {
// books コレクションのドキュメントに updatedAt フィールドがなければ何もしない
return false
}
const metaUpdated = await lastUpdatedTimeOfMeta()
// メタ情報が books コレクションより古ければ更新する必要がある
return metaUpdated == undefined || bookUpdated > metaUpdated
}集計情報を差分更新する
Cloud Functions の Cloud Firestore トリガー を使うと、Firestore データベースの任意のドキュメントが更新されたときに関数を呼び出すことができます。
exports.bookUpdated = functions.firestore
.document('books/{bookId}')
.onWrite((change, context) => {
// context.params.bookId == "001";
// ... and ...
// change.before.data() == {tag: "Old Tag", ...}
// change.after.data() == {tag: "New Tag", ...}
});
これを利用すると、更新されたドキュメントの内容(更新前と更新後の値)を随時取得できるので、その差分情報を使ってメタ情報をリアルタイムに更新することができます。 ただし、積み上げの形でメタ情報を更新していくことになるので、整合性が保たれるように注意しなければいけません。
タグが完全に削除されたことを検出するためには、メタ情報としてタグの参照カウンタを保存しておくといった変更も必要になるでしょう。
tags:
"Tag1": 7
"Tag2": 10
"Tag3": 0上記の Tag3 のように、そのタグの参照数カウンタが 0 になったらそのタグはもう存在しないとみなします。
このように、差分更新は複雑で慎重に扱う必要があるので、定期的な集計で済むのであればそちらの手法を使った方が簡単です。 ある程度の整合性を保ちながら、メタ情報をリアルタイムに更新していく必要がある場合は、両者の手法を組み合わせて使う方法も考えられます。 例えば、ドキュメントの更新時にメタ情報を差分更新しつつ、1 日 1 回程度の定期的な集計処理で整合性を担保します。