ストレージアカウントを作成する
Table Storage や BLOB Storage などの個々のストレージ系サービスは、ストレージアカウントに紐づく形で管理されます。 まずは、ストレージアカウントを作成しておく必要があります。
Table Storage にテーブルを作ってみる
テーブルの作成
上記で作成したストレージアカウントを選択し、Table Service → テーブル を選択し、作成 ボタンを押すと、Table Service 上に新しいテーブルを作成することができます。
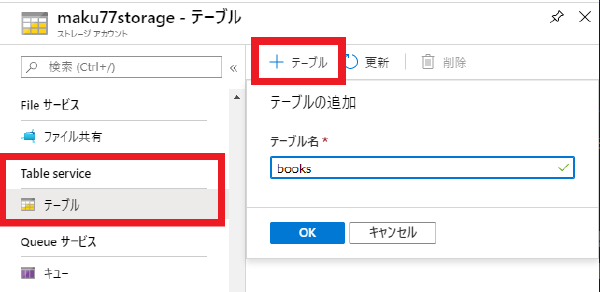
ここでは、書籍を管理するための、books テーブルを作成してみました。
エンティティの追加
テーブルができたら、そこに適当にデータを追加していきます。 Table Strorage では、テーブル内の個々のデータのことを「エンティティ」と呼びます(RDB でいうレコードです)。
ストレージアカウントのメニューにある、「Storage Explorer」を使ってエンティティを追加できます。
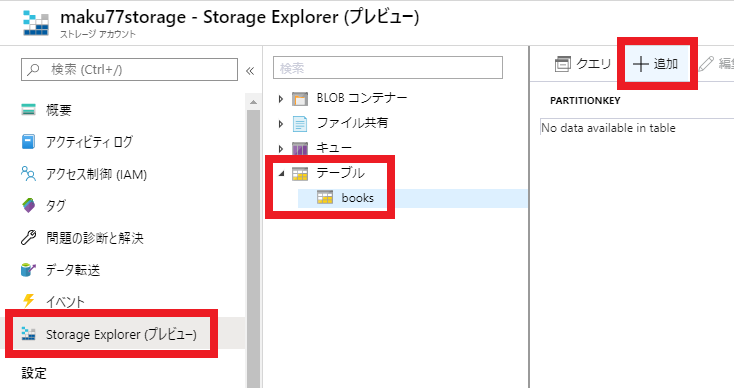
「エンティティの追加」ダイアログが表示されるので、ここでエンティティの情報を入力していきます。
デフォルトでは、PartitionKey と RowKey というプロパティ(RDB でいうフィールド)が定義されていますが、本の情報を入力するために、タイトル (Title) と著者 (Author) のプロパティを追加しておきます。
プロパティ名は、C# の慣例に従って、単語の先頭を大文字で始める CamelCase で定義 しておくのがよいようです(C# から使うとは限らないのですが^^;)。
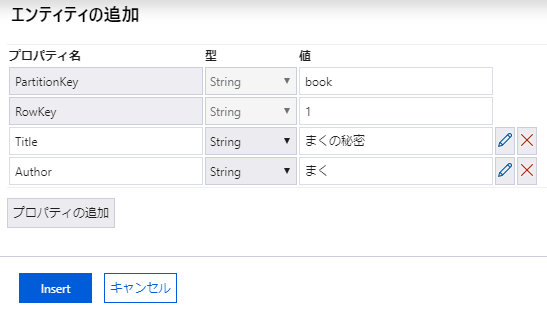
最初のデータとして次のように入力してます。
- PartitionKey : book
- RowKey : 1
- Title : まくの秘密
- Author : まく
PartitionKey と RowKey は、Table Storage がデフォルトで用意する文字列型プロパティで、これらを組み合わせたものがテーブル内でデータを一意に特定する情報になります(RDB のプライマリキーのようなもの)。
詳しくは後述しますが、ここでは単純に book というパーティション名を付けています。
ここでは、次のように 3 つのエンティティを登録してみました。

データの登録時間を示す Timestamp というプロパティが自動的に付加されるみたいですね。
上記の例では、RowKey に 1 という数字を入れてしまっていますが、PartitionKey も RowKey も文字列データとして扱われるため、 数字であれば 0000001 のような 0-padding した固定長のデータとして格納すべき とされています(参考)。
If you are using an integer value for the key value, you should convert the integer to a fixed-width string, because they are canonically sorted. For example, you should convert the value 1 to 0000001 to ensure proper sorting.
固定長にしておかないと、ソート処理で文字ベースの比較が行われるため、100 が 50 よりも小さいとみなされてしまいます。
PartitionKey と RowKey について
Table Storage のテーブル設計は、PartitionKey と RowKey にどのような値を入れるかがパフォーマンス上の重要なファクターになってきます。
- PartitionKey
- テーブル内のエンティティが所属するパーティションを指定します。PC のストレージのパーティションと同じような概念で、データ取得時(検索時)には、内部的にこの
PartitionKeyの範囲で検索することになります。同一のパーティションに含まれるデータは、1回のクエリで取得することができます。 - RowKey
- RDB のプライマリキーに相当するものです。任意の文字列を指定できますが、同一の
PartitionKeyの中で一意になるようにしなければいけません。Table Storage 用の検索クエリを用いると、この値の大小比較によるデータ検索を行うことができます。
Table Storage はこの 2 つを組み合わせて内部でインデックスを作成するため、Table Storage から高速にデータを取得するためには、なるべくこの 2 つの値を指定して検索できるように設計しなければいけません。
テーブルのプロパティをどのように定義するかのガイドラインは、下記の Azure Table Storage ドキュメントに記載されています。 中でも、「テーブルの設計パターン」はたくさんの事例とノウハウが記載されていて参考になります。
例えば、ログデータであれば、PartitionKey に「年月」の情報を入れておけば、月単位のログ分析が効率的に行えるようになります。
しかし、頻繁な書き込みが発生する場合は、PartitionKey が「月」の情報になっていると、同一のパーティションに書き込みが集中し、パフォーマンスが低下します(Microsoft ではこれを ホットパーティション と呼んでいます)。
そのため、別のパーティションに書き込みが分散されるように、ParitionKey に「部署名」のようなものを入れる設計が考えられます。
- PartitionKey : 部署名
- RowKey : 日時+イベントID
これで書き込みは部署ごとに分散されるようになるのですが、今度は、日時指定でデータ取得したいときに、複数のパーティションにまたがったデータ取得が実行されるため効率が悪くなるという問題が発生します。
というわけで、ログデータに関しては PartitionKey と RowKey をどのように設計しても一長一短があり、上記ドキュメントでは BLOB ストレージを推奨しています(なにーっ!)。
データを冗長化して持たせるという思想は、RDB でテーブルを正規化してきた人にとっては受け入れにくい考え方かもしれませんが、NoSQL の世界では一般的な考え方なので慣れるしかありません。 データありきではなく、Usage ドリブンでうまくデータを作っていくということですね。